本文主要介绍整数相关的三个问题:类型转换、符号位扩展、数据截断。
通过本文可以了解到以下信息:
- 类型转换并不改变原数据的内存模型,只是改变了这块内存的解读方式。
- 从长度较小的类型转换为长度较大的类型,为了保持数值不变,必须进行符号位扩展。
- 从长度较大的类型转换为长度较小的类型,会导致数据截断,即把原数据的补码根据目的类型的长度进行截断,丢弃高位数据,保留低位数据,期间不进行任何语义解析。
- 除了编译器没人关心数据类型(解释型语言除外),它根据不同的类型使用不同的指令。
一、预备知识
本章简单介绍补码、补码的减法运算相关知识点。
了解这些内容,有助于理解本文。如果已经对相关内容比较熟悉,可以直接跳到第二部分。
1. 2的补码
在计算机中,整数是用2的补码表示的,其定义如下(非官方定义,自己总结的):
- 最高位(首位)是符号位,为0代表正数,为1代表负数
- 对于非负整数(大于等于0的整数),其补码等于原码(也就是说,直接将该整数转换为2进制,即为补码)
- 对于负数,其补码等于对应正数的补码按位取反后加1
注:正数的原码、反码、补码是相同的,这里不再展开。
2. 十进制转换为2的补码
假设系统为32位,十进制整数12345的补码如下(即0x3039):
0000 0000 0000 0000 0011 0000 0011 1001
那么-12345的补码是多少呢?
12345的补码按位取反后如下(即0xFFFF CFC6):
1111 1111 1111 1111 1100 1111 1100 0110
再加1即得到-12345的补码,如下(即0xFFFF CFC7):
1111 1111 1111 1111 1100 1111 1100 0111
同样,我们常用的-1,其补码为0xFFFF FFFF,也就是全1。
3. 2的补码转换为十进制
2的补码转换为十进制的方法如下:
- 若符号位为0,则该数为正数,直接转换为十进制即可
- 若符号位为1,则该数为负数,需先将该数减1,然后取反,得到的数转换为十进制,即为原负数的绝对值
若一个补码如下:
0000 0000 0000 0000 0011 0000 0011 1001
该数最高位为0,所以为正数,可直接转换为十进制的12345.
若一个补码如下:
1111 1111 1111 1111 1100 1111 1100 0111
该数最高位为1,所以为负数,只能先求其对应正数的值。
先将该数减1得到:
1111 1111 1111 1111 1100 1111 1100 0110
再取反得到:
0000 0000 0000 0000 0011 0000 0011 1001
上面二进制对应的十进制整数为12345,由此可以得到原补码对应的十进制数为-12345。
4. 减法运算
利用补码,可以将减法运算转换成加法运算。
例1:结果为正数的减法
以下面的减法为例:
12345 - 1
它等价为:
12345 + (-1)
将12345和-1分别转换为补码表示:
(0000 0000 0000 0000 0011 0000 0011 1001) + (1111 1111 1111 1111 1111 1111 1111 1111)
上式的计算结果为:
1 0000 0000 0000 0000 0011 0000 0011 1000
注意它产生了一个进位,该数值总共占用33位,已经溢出。
除去溢出位,剩余的0000 0000 0000 0000 0011 0000 0011 1000即为十进制的12344。
例2:结果为负数的减法
以下面的减法为例:
1 - 12345
它等价为:
1 + (-12345)
将1和-12345分别转换为补码表示:
(0000 0000 0000 0000 0000 0000 0000 0001) + (1111 1111 1111 1111 1100 1111 1100 0111)
上式的计算结果为:
1111 1111 1111 1111 1100 1111 1100 1000
该数最高位为1,所以是个负数。根据前面介绍的转换规则,转为十进制后为-1234。
二、整数在程序中的表示
本章以下面的代码为例,看看整数在汇编代码和运行期的形态。
#include <stdio.h>
int main()
{
int signed_int = -12345; /* 补码为0xffffcfc7 */
unsigned int unsigned_int = 12345; /* 补码为0x3039 */
printf("%d %u\n", signed_int, unsigned_int);
return 0;
}
1. 整数在汇编代码中的表示
以arm平台为例进行分析,使用下面的指令对a.out进行反汇编:
helloworld@ubuntu:~$ arm-linux-gnueabihf-gcc -g main.c --static
helloworld@ubuntu:~$ arm-linux-gnueabihf-objdump -d a.out > a.txt
main函数对应的汇编代码如下所示,其中
- 指令
movw将16bit的立即数搬移到寄存器的低16位,并将寄存器的高16bit清零 - 指令
movt将16bit的立即数搬移到寄存器的高16位
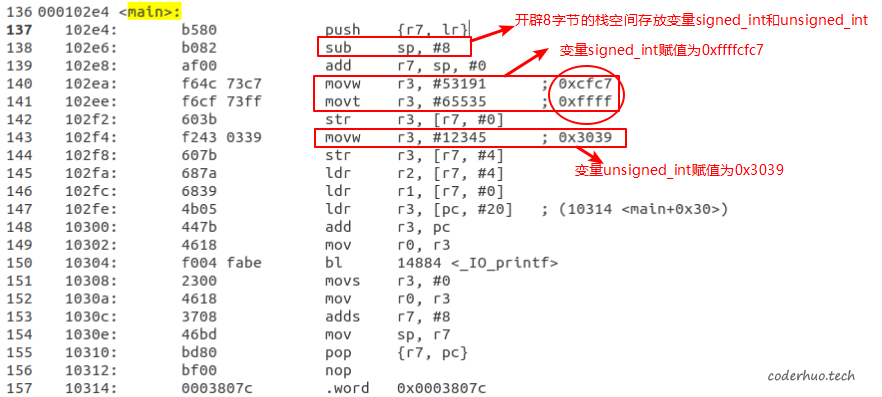
从main函数的汇编代码中可以得到以下信息:
- 汇编代码中,已经把立即数
-12345和12345翻译成了补码,分别为0xffffcfc7、0x3039,均占用4个字节。 - 汇编代码中不会保存变量名称,仅仅把相关变量放到对应的内存地址。上图142行和144行分别将立即数-12345和12345放到各自的内存区域。
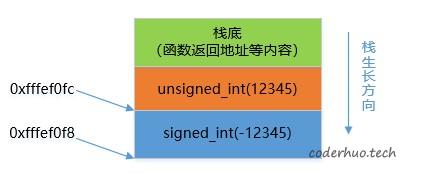
-12345在内存的低地址,12345在内存的高地址,示意图如下(局部变量入栈顺序受优化等级、栈保护等因素影响,不应对入栈顺序做任何假设):
2. 整数在内存中的表示
通过gdb可以看到变量signed_int和unsigned_int在内存中的信息如下所示:

- signed_int和unsigned_int位于连续的8字节内存区域中,其中signed_int在低地址处(当前栈帧的栈顶),和上面的栈示意图一致
- 内存中存储的就是对应数字的补码(小端序存储)
三、对整数的解读
从上面我们可以看到,无论是正数还是负数,在内存中都是以2的补码的形式存在的。那么,在不同场景下,程序是如何解读这块内存区域的呢?
1. 函数printf
下面的代码输出为-12345 4294954951,其中十进制的4294954951转换为十六进制为0xffffcfc7。
#include <stdio.h>
int main()
{
int signed_int = -12345; /* 补码为0xffffcfc7 */
unsigned int unsigned_int = signed_int;
printf("%d %u\n", signed_int, unsigned_int);
return 0;
}
从下图可以看到,变量signed_int和unsigned_int在内存中完全一样。输出结果不同,是由于printf根据格式化字符串(如%u、%d等)对内存中的数据进行解析,并将解析结果输出。也就是说,内存中同样的内容,按照不同的规则解读(格式化字符串不同),会输出不同的内容。

2. 整数比较大小
下面的代码,大家都知道为啥输出结果不一样,因为右边的int被提升为unsigned int,-12345被解析成了4294954951,所以大于1。
但类型转换是如何做到的呢?从gdb信息可以看到,两份代码中变量a、b在内存中是一样的。
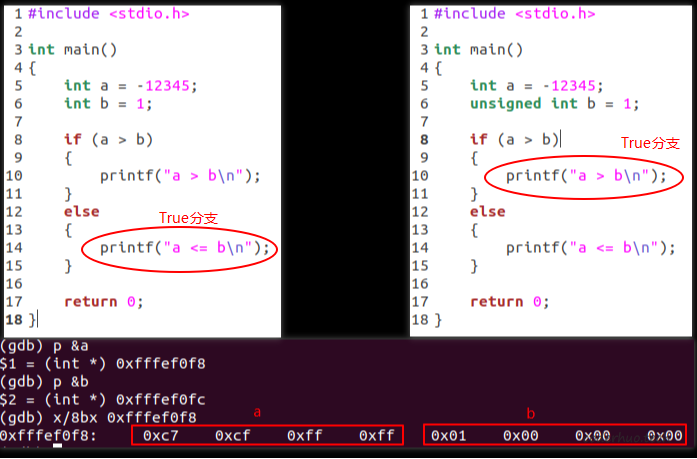
我们再对比下二者的汇编代码:
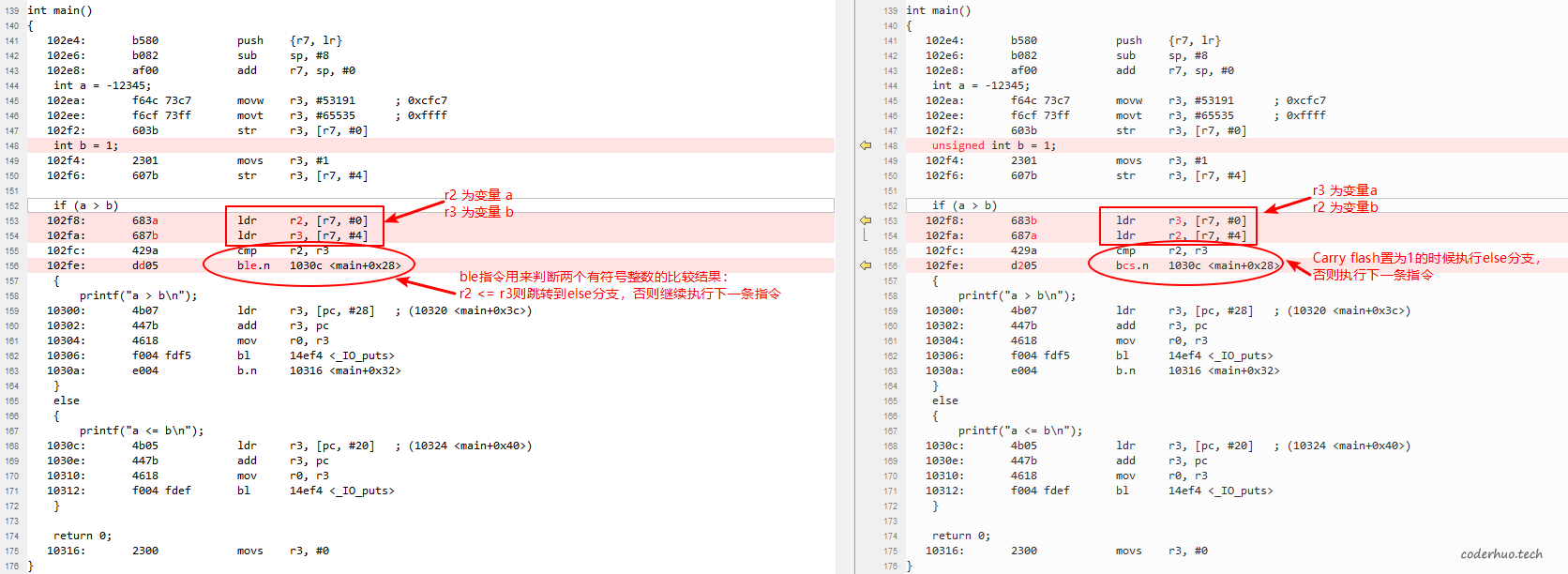
可以看到以下信息:
- 两份汇编代码中都是使用cmp指令比较两个数的大小,而该指令只是把两个操作数做减法(减法原理上面已经介绍了),然后根据运算结果将一些状态(比如是否进位)记录在状态寄存器中。
- 用来判断比较结果的指令不同,左侧是ble,右侧是bcs。这两个指令都是根据cmp设置的状态寄存器中的flag做判断,看哪个数大,哪个数小。
看来编译器才关心数据类型,它根据不同的类型使用不同的指令。左侧的ble指令比较直观,就不再展开了。对于右侧的bcs,我们简单理下过程:
cmp r2, r3
= r2 - r3
= b - a
= 1 - (-12345)
= 1 + 12345
= 0000 0000 0000 0000 0011 0000 0011 1010
我们看到计算结果无溢出,而bcs只有在计算结果溢出的时候才会执行else分支,所以程序未跳转,继续向下执行,打印出了a > b的结果。
3. 符号位扩展
我们知道,补码和数据类型的长度是有关的:
- 如果类型长度是1字节,-1的补码是0xFF
- 如果类型长度是4字节,-1的补码是0xFFFF FFFF
那么,从长度较小的类型转换为长度较大的类型的时候,为了保持数值不变,必须进行符号位扩展:
- 对于正整数,符号位为0,扩展前后不变
- 对于负数,符号位为1,新扩充的位(高位)全部用1填充。
举例如下(加粗部分为扩展出来的位数,即在原数值的高位进行扩展):
char类型的1的补码为 0000 0001,转换为int类型后的补码为:0000 0000 0000 0000 0000 0000 0000 0001
char类型的-1的补码为 1111 1111,转换为int类型后的补码为:1111 1111 1111 1111 1111 1111 1111 1111
那么,符号位扩展是如何实现的呢?我们通过下面的代码一探究竟:
#include <stdio.h>
int main()
{
signed char a = -1;
int b = (int)a;
printf("b:%d\n", b);
return 0;
}
上面的代码并未输出255,而是-1。也就是说在符号位扩展的时候,保持值不变。
从下面的汇编代码中我们可以看到:
- 变量a赋值是0xff
- 变量b赋值的时候是用ldrsb命令把a的值读到寄存器r3,然后再存储到对应的内存。而该指令的作用就是从内存中加载一个字节,并进行符号位扩展,扩展到32位。
- 另外,从142行可以看到,栈空间分配了8个字节。
signed char实际上也占用了4个字节,这就是按字长对齐(32位系统字长为4字节,64位为8字节)。

接下来我们看看运行时的调试信息:
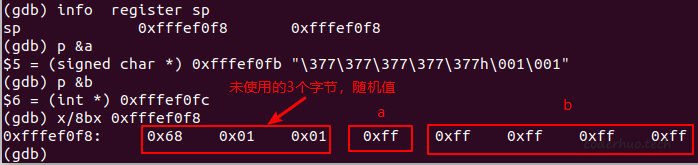
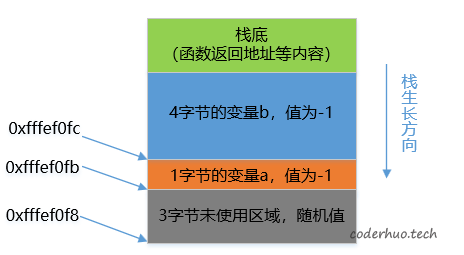
从上面我们可以看到,a和b在内存中的关系如下图所示,注意两点:
- 为了内存对齐而填充的3个字节是随机值,如果不小心用到会出莫名其妙的问题。这也是为什么要求变量必须初始化的原因。
- 变量a被放在了4字节的高字节处,这是小端机的做法,大端机会放在低字节处。(结合前面的整数解读部分,运行期判断大小端的原理是不是就一目了然了)
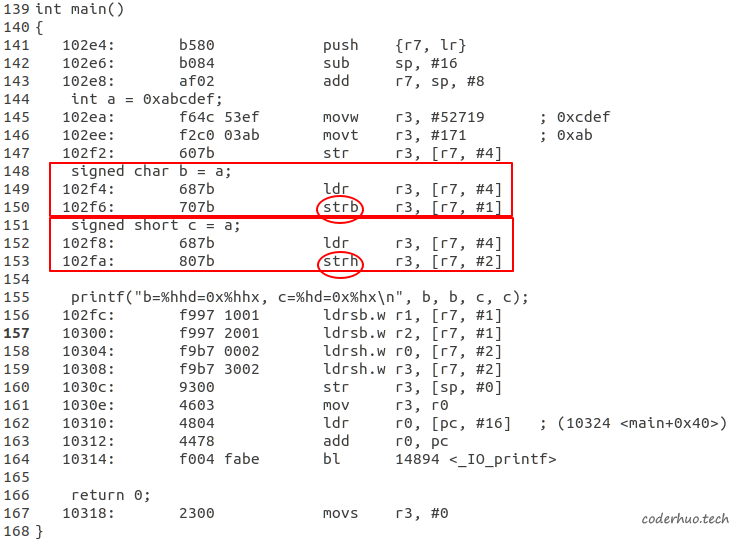
4. 数据截断
以下面的代码为例:
#include <stdio.h>
int main()
{
int a = 0xabcdef;
signed char b = a;
signed short c = a;
printf("b=%hhd=0x%hhx, c=%hd=0x%hx\n", b, b, c, c);
return 0;
}
其输出为:
b=-17=0xef, c=-12817=0xcdef
变量a在内存中表示为0xabcdef,占用4字节。若目的类型长度为1字节,截断后在内存中表示为0xef;若目的类型长度为2字节,截断后在内存中表示为0xcdef。
从下面的汇编代码可以看到,变量b和c的赋值流程基本相同,都是先把a的值加载到寄存器r3,不同的是前者调用了strb指令,后者调用了strh指令。strb是将寄存器所存储数值的最低位一字节写到内存中;strh是将寄存器所存储数值的最低位二字节写到内存中,并且保持这二字节的相对顺序不变。
也就是说,数据截断,是把原数据的补码根据目的类型的长度截断,丢弃高位数据,保留低位数据,期间不进行任何语义解析。
好了,本文到此结束。回过头来看看文章开头的结论,理解的是否深刻点了?
- 类型转换并不改变原数据的内存模型,只是改变了这块内存的解读方式。
- 从长度较小的类型转换为长度较大的类型,为了保持数值不变,必须进行符号位扩展。
- 从长度较大的类型转换为长度较小的类型,会导致数据截断,即把原数据的补码根据目的类型的长度进行截断,丢弃高位数据,保留低位数据,期间不进行任何语义解析。
- 除了编译器没人关心数据类型(解释型语言除外),它根据不同的类型使用不同的指令。
