车载软件开发调试,不可能每次都出车路测,否则成本太高。
apollo中提供了cyber_recorder工具,可以将报文录制下来,保存为文件。这样,实际路测的时候,可以把相关报文保存下来,后续可以通过报文回放进行开发调试。
本文主要基于apollo v6.0介绍cyber_recorde的报文录制功能。
cyber_recorder录制的文件结构如下图所示,各组成部分由protocolbuffers描述,protocolbuffers文件路径为cyber/proto/record.proto。下面介绍几个重要的组成单元:
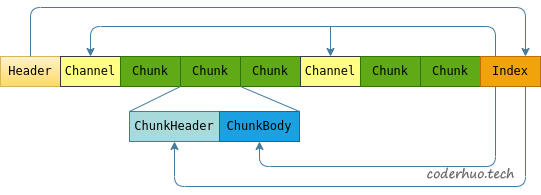
- Header:文件头部信息,用来描述整个文件的信息。
- Header位于文件的开始部分
- Header中指明了索引区Index的位置
- 文件头部最大长度是2048字节,未使用部分用0填充(首个字符填充的是字符
0),文件cyber/record/file/record_file_base.h中的const int HEADER_LENGTH = 2048做了相关限制。 cyber/record/header_builder.cc中的函数proto::Header HeaderBuilder::GetHeader()定义了header的默认值- 文件创建的时候会先把Header写入文件,但是由于Header中包含可变部分(比如chunk_number等),随着程序的运行Header的值会发生变化,所以内存中也维护了一份Header的内容,文件关闭前再写入到文件(中途如果出现异常可能导致录制文件无法打开)。
-
Channel:通道信息,定义如下所示。接下来以cyber/examples/目录下的talker.cc、listener.cc为例解读相关含义。
message Channel { optional string name = 1; optional string message_type = 2; optional bytes proto_desc = 3; }- name为本通道的topic名称,即channel/chatter
- message_type为talker.cc、listener.cc所使用的protocolbuffers文件
cyber/examples/proto/examples.proto - proto_desc用来反序列化Chatter对象,它由protocolbuffers框架根据examples.proto文件生成(protocolbuffers的反射机制)
- 每个存储下来的消息都要和一个Channel做关联,这样报文回放的时候,才可以根据Channel反序列化为消息对象。
- Channel信息是在本通道首次上线(被监听的Writer创建的时候)的时候才写入到文件中,这就导致Channel在文件中的位置是不确定的。比如打算录制a和b两个通道的消息,a通道一开始就在线,b通道过了很久才上线,这种情况下录制文件的结构是:Header、a的Channel信息、a的若干个Chunk,然后才是b的Channel信息。所以,Channel的读取需要依赖Index建立的索引。
- Chunk:报文存储区域,每个Chunk包含多个报文,一个录制文件可能由多个Chunk组成。record.proto中并不存在Chunk这个结构,而是用ChunkHeader和ChunkBody两部分来表示。
- record.proto中的Header.chunk_interval用来控制Chunk分割逻辑,cyber_recorder工具并没有提供设置接口,默认值是20s。这样分段有一个好处,读取的时候,可以按照Section一块一块读取。
- ChunkHeader中描述了本Chunk所含报文的起止时间、数量等信息,Index中有索引指向每个ChunkHeader,这样按时间查找报文就很方便(比如按时间段回放报文)。
- ChunkBody中则是录制下来的一个一个的报文,由SingleMessage来描述。
-
SingleMessage:消息存储结构,定义如下所示。继续以talker.cc、listener.cc为例说明各个字段含义:
message SingleMessage { optional string channel_name = 1; optional uint64 time = 2; optional bytes content = 3; }- channel_name:本通道的topic名称,即channel/chatter,通过该字段,可以找到前面提到的Channel信息。
- time:接收端收到该报文的时间。TBD:这里使用的是接收到消息的时刻,而不是消息产生的时刻,感觉不太合理,不知是否有其他考虑。
- content为RawMessage,即examples.proto中Chatter的protocolbuffers表示,该字段可以经由Channel中的proto_desc反序列化为Chatter对象。
- Index:索引信息,位于尾部(Header中的index_position字段指向Index的起始位置),平时只是维护在内存中,只有在文件关闭前才会写到文件中(报文录制过程中如果出现异常可能导致录制文件无法打开)。共有三种索引:
- 指向Channel的索引
- 指向ChunkHeader的索引
- 指向ChunkBody的索引
以上大致介绍了cyber_recorder所录制文件的逻辑结构。实际上,在上图所示的Header、Channel、ChunkHeader、ChunkBody前面,都有个Section的结构,它的定义位于cyber/record/file/section.h中,比较简单,只包含类型和长度,类型由record.proto中的SectionType定义,长度代表本section的长度。加上这个结构,读取文件的时就可以很方便的以Header、Channel、ChunkHeader、ChunkBody或者Index为单位进行读取。
其他:
- 录制文件可以按时间分段也可以按大小分段,文件
cyber/record/record_writer.cc中的RecordWriter::SplitOutfile负责文件切片段。 - RecordWriter中的统计信息统计的是可执行文件cyber_recorder的一次运行,RecordFileWriter中的统计信息统计的是一个记录文件;文件切片段的时候 RecordWriter中的统计信息不reset,RecordFileWriter中的统计信息reset(对象都重新生成了)
- 单个录制文件可能包含多个通道(Channel),这些通道的消息起点和发送频率可能都是不同的;另外,回放的时候,还有可能同时回放多个文件(一个文件对应一个RecordReader对象),这些文件可能包含若干个通道。这就涉及多通道回放时不同通道间的时间同步问题,
cyber/record/record_viewer.cc就是用来处理这个事情的。
