本文介绍在共享内存中自建hash的一种方法。
下图所示的共享内存有一个writer和多个reader,为了提高数据存取效率,共享内存中的数据需要按hash组织。
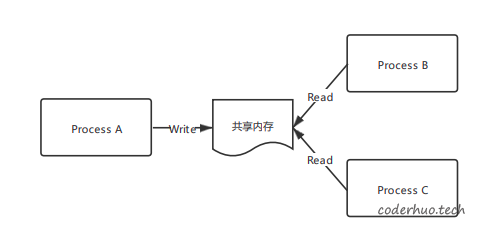
注:本文不讨论writer和和reader之间的同步问题,具体可由信号量、文件锁等方式实现。
初步想法是将整块共享内存划分成一个下标为0~n的数组,如下图所示。数据Record的key经过Hash计算后得到hashcode,然后将该值映射为数组的下标,直接通过下标访问数组,将Record的key和value存储在对应的位置。
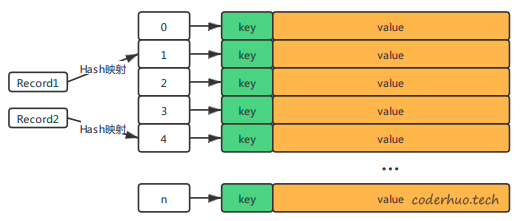
但是Hash存在冲突的情况,即两个不同的Record经过Hash映射,得到的下标可能是相同的。
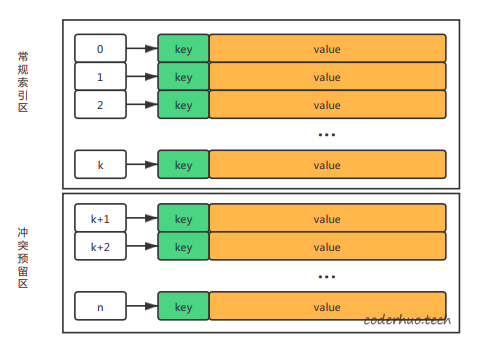
为了处理这种情况,需要将共享内存分区,一部分作为常规的Hash索引区,另一部分作为冲突预留区,用来保存hash冲突的Record。如下图所示,具体比例可以根据业务的数据情况调整,如果冲突较多就保留较大的预留区,否则预留区可以小一点,比如按1:1划分或者2:1划分。
注:冲突较多的时候,可以考虑换hash函数。
数据写入流程如下:
- 假设Record1经过Hash映射后落在了下标为0的存储单元,该存储单元当前未被占用,直接存储
- 接下来Record2经过Hash映射后也落在了下标为0的存储单元,这时候从预留区找一个空闲节点(比如下标为k+1的存储单元),将Record2存储在该空闲节点,并建立下标0到k+1的单向链表(方便后续查找)
- 一段时间后Record3经过Hash映射后也落在了下标为0的存储单元,这时候再从预留区找一个空闲节点(比如下标为k+n的存储单元),将Record3存储在该空闲节点,并建立从下标0到k+1,再到k+n的单向链表。
最终建立了下图所示的链接关系:
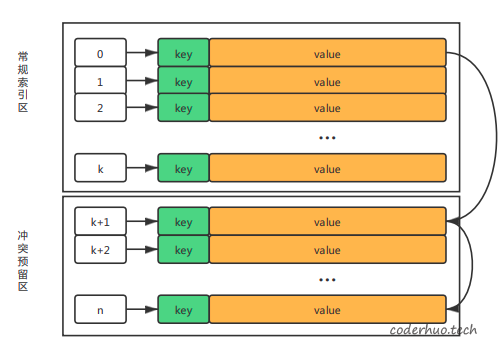
说明:
- 如果预留区已经没有空闲存储单元,只能报错了
- 预留区的空闲节点也可以组织成一个单向链表(空闲存储单元链表),当遇到Hash冲突时从该链表摘取节点,当节点不再使用的时候,再归还到该链表中
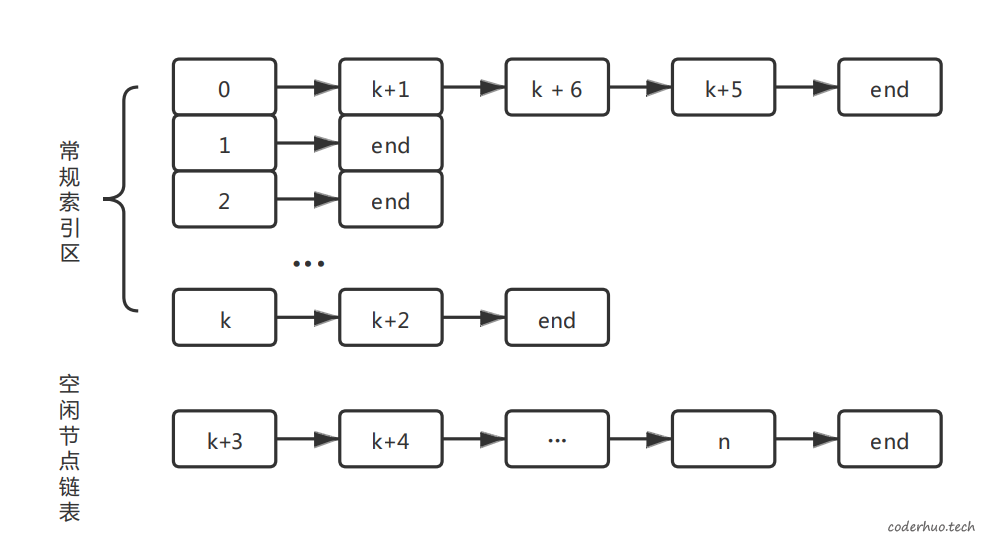
从上面的介绍可以看出,其实最终整个数组被划分成了下图所示几个链表:
- 0~k是常规的Hash索引区
- Hash函数及映射规则决定了这一区域包含几条链表
- 这些链表至少包含一个头节点,即使该节点没被占用也不能放到空闲列表中
- 每条链表的长度是不固定的,默认只包含一个头节点,运行期间动态的增加、删除节点
- 最后一条链表是为了解决hash冲突预留的节点,运行过程中,会根据需要动态的添加到上面0~k链表的后面,当数据释放的时候,再归还到空闲列表
数据读取过程:把key做hash映射,得到对应的数组下标,也就知道了该在哪个链表中找数据,依次遍历对应的链表,比较key是否一致,如果一致就找到了对应的记录。
数据删除过程:
- 先按数据读取流程找到对应的数据存储单元
- 如果该存储单元不是头节点,直接将该节点从链表中摘除,放到空闲链表中
- 如果该节点是头节点
- 该链表只有一个头节点的情况下,直接标记为空闲状态即可
- 如果链表除了头节点还有其他节点,由于头节点不能摘除,那就把尾节点的数据拷贝到头节点,将尾节点从链表中摘除,放到空闲链表中
