本文主要分享一个Cache一致性踩内存问题的定位过程,涉及到的知识点包括:backtrace、内存分析、efence、wrap系统函数、硬件watchpoint、DMA、Cache一致性等。
1 背景
设备上跑的是嵌入式实时操作系统(RTOS,具体为商业闭源的ThreadX),非Linux平台,导致一些常见的问题排查方法无法使用。
问题描述: 重启压力测试时,发现设备启动过程中偶尔会死机,概率较低。稍微修改程序后,问题可能就不再出现了,所以版本回退、代码屏蔽等方法不太适用。
2 基于backtrace分析
由于平台局限性,不支持gdb等常用调试方法,为了便于定位死机问题,本平台引入了backtrace机制,在死机的时候,会自动回溯出函数调用栈。
2.1 原理
本平台的backtrace并不是基于libc的(平台不支持),而是采用很原始的方法,当程序异常时,捕获PC寄存器和SP寄存器的值,依次回溯栈帧,从栈帧中搜索历史PC指针,进而还原出函数调用栈。
具体可以参阅:arm平台根据栈帧进行backtrace的方法
2.2 分析
死机时的堆栈如下:
Oops: CPU Exception!
pc : [<0xa000a8ac>]lr : [<0xa000a884>]
sp : 0xa37a60d8 ip : 0xa37a60d8 fp : 0x0000000b
r10: 0xa37a62c4 r9 : 0xa0fe9ab0 r8 : 0x00000000
r7 : 0x00000000 r6 : 0xa37a61c0 r5 : 0x00000000
r4 : 0x0000006c r3 : 0x00000075 r2 : 0xa0fe9630
r1 : 0x600001d3 r0 : 0x60000113
==level:0 pc:a000a8ac sp:a37a60d8==
find push in[0xa000a834], register_num=8, stack_frame_size=32
this frame size is 32
==level:1 pc:a046e900 sp:a37a60f4==
find push in[0xa046e8f0], register_num=2, stack_frame_size=8
this frame size is 8
==level:2 pc:a046b184 sp:a37a60fc==
find sub in[0xa046b0a8], stack_frame_size=228
find push in[0xa046b0a4], register_num=9, stack_frame_size=264
this frame size is 264
==level:3 pc:a040d3f4 sp:a37a6204==
find sub in[0xa040d28c], stack_frame_size=108
find push in[0xa040d288], register_num=7, stack_frame_size=136
this frame size is 136
==level:4 pc:a03e676c sp:a37a628c==
find sub in[0xa03e65dc], stack_frame_size=340
find push in[0xa03e65d4], register_num=9, stack_frame_size=376
this frame size is 376
==level:5 pc:a040b3ac sp:a37a6404==
backtrace end
PC指针0xa000a8ac对应的反汇编代码如下,可以看出,是死在了_txe_semaphore_create函数中(从上面的打印信息可以看出r5寄存器的值是0x00000000, 从下面的反汇编代码可以看出死机时在尝试访问该值偏移20字节的内存地址)。通过上面的各级PC指针进行回溯,发现回溯出来的函数都是有效的(栈被破坏的情况下,回溯出来的调用栈可能是无效的,后面会提到)。
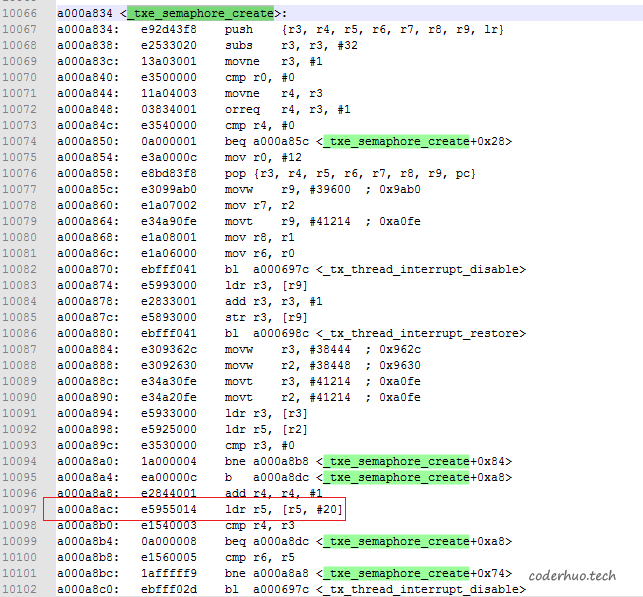
虽然ThreadX不是开源的,但我们有幸在github上找到了一份开源代码,而且这份代码和我们的反汇编基本上能对应起来。_txe_semaphore_create的源码(经过裁剪,仅为示例,实际代码以参考文档1为准)如下:
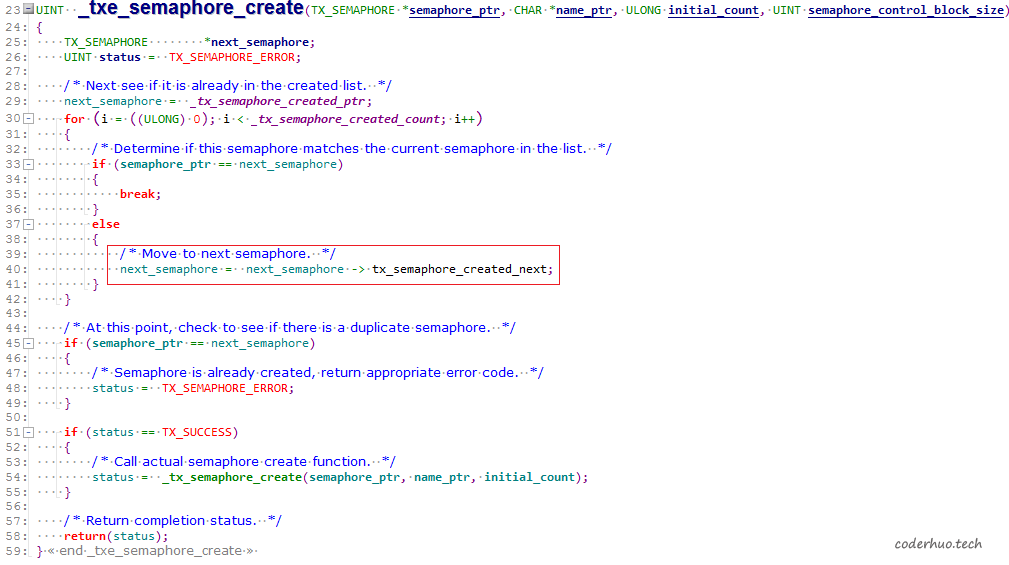
而结构体TX_SEMAPHORE定义如下:

tx_semaphore_created_next在结构体TX_SEMAPHORE中正好位于起点偏移20字节的地方,结合反汇编,可以推断异常发生在函数_txe_semaphore_create中下面的语句:
next_semaphore = next_semaphore -> tx_semaphore_created_next;
其中右边的next_semaphore(即寄存器r5)为NULL。
从这里可以看出,有信号量被破坏了。显然,这里只是问题的表象,根因并不在这里。
出问题的时候,系统中共有一百多个信号量,另外,程序运行过程中会动态的创建/销毁信号量,目前无法确定是哪里的信号量出了问题。
接下来,我们需要确认这个信号量是谁创建的?
3 确定受害者身份
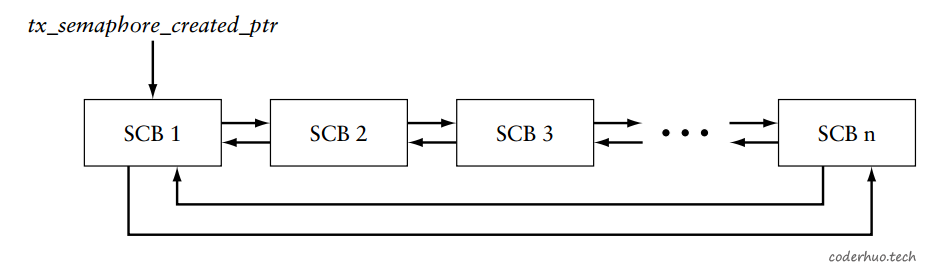
3.1 ThreadX的信号量管理机制
从源码可以看出,ThreadX的信号量是以双向链表的形式维护的,如下图所示(SCB是Semaphore Control Block的简称,其实就是上面的结构体TX_SEMAPHORE)。_tx_semaphore_created_ptr指向表头,另外有个全局变量_tx_semaphore_created_count说明当前总共有多少个信号量。
正常的信号量在内存中如下图所示,红框中为一个完整的信号量。信号量结构体中第二个字段是信号量名称,可惜我们使用的接口是被二次封装过的,无法设置信号量的名字,否则可以根据名字知道哪个信号量出问题了。

3.2 分析
我们可以在死机的时候,遍历信号量链表,检查现存的信号量,看看哪个出问题了。同时可以把每个信号量及其周边的内存dump出来,或许可以从这里面找到一些信息。
根据上面的思路复现后,发现某个信号量(红框内,首地址位于内存地址0xa394554c)变成了下面这个样子,面目全非了,最前面的magic等都被破坏了。从这里识别不出来这个信号量是哪里创建的。

不过,我们的程序托管(非hook,只是基于系统接口重新封装了一套接口)了内存申请/释放的接口,死机的时候会把当前已申请但还未释放的内存打印出来。打印信息如下,其中包含了函数名、行号、线程号、申请的内存大小、地址等信息:
[func1: 870:0xa1861368] malloc:0 bytes. offset:0 ptr:0xa394554c
[func2:2252:0xa1861368] malloc:4 bytes. offset:c ptr:0xa39455a0
可以看到,首地址为0xa394554c的内存块是由func1动态申请的。但是func1是个通用接口函数,好在只有四个地方调用了该接口,排查范围一下子缩小了很多。
注:上面的size为0,是因为该值是从内存中直接解析出来的,从这里也可以看出该内存区域被破坏了,导致解析出来的内存块大小异常。后面介绍内存标记后就可以理解这里的值为啥会为0。
排查代码未发现异常,那就继续添加调试信息。在每个调用func1的地方把创建的信号量地址打印出来,复现后和被破坏的信号量地址比较。这样修改后,可能是因为影响了代码的执行顺序,变得难复现了。好在还是复现出来了,最终确定了被踩信号量的身份。
后来经过多次复现,发现被踩的总是这个信号量,但是被踩后该区域的内容都是无规律的,也就是说从内存痕迹看不出是谁踩了这里。
4 谁踩了这个信号量
我们目前分析到的信息如下:
- 被踩区域是动态申请的,内存地址是不固定的,但总是那个可怜的信号量所在的地方。
- 代码走查发现,该信号量创建后只在特定情况下才会使用,从启动到设备出问题应该是没人用过的。
前面提到我们托管了内存申请/释放的接口,所以可以知道受害信号量前后的内存是哪里分配的。排查相关代码,均无内存越界的可能性。也就是说,临近的内存不会越界伤害到这个信号量。难道是飞来横祸,某个野指针恰好落在了这个区域?
这时候,首先想到的就是内存保护。如果能像linux那样调用mprotect函数,把这块内存设为只读属性,谁往这里写东西就会触发异常,通过调用栈可以抓到凶手。
可惜我们的平台没有mprotect这类函数。后来从驱动组同事那里了解到,可以直接通过该平台提供的MMU操作接口设置内存的只读属性。写了个demo,确实可以正常工作。
但是我们忽略了一个问题:上面提到信号量是以双向链表的形式维护的,信号量的动态创建/销毁都会操作链表,也就是会对信号量所在内存区域进行写操作,所以我们没法对信号量本身进行保护。
那么,我们是否可以借鉴Linux下Electric Fence的原理进行内存越界检测呢?
4.1 利用Electric Fence原理进行定位
Electric Fence(简称efence)是Linux平台定位堆内存非法访问问题的利器,它的优势在于事前报警而非事后,直指第一现场。efence就是基于MMU的内存访问属性来实现的,可以检测上边界溢出、下边界溢出、访问已释放内存(野指针)等问题,具体可以参考https://linux.die.net/man/3/efence。
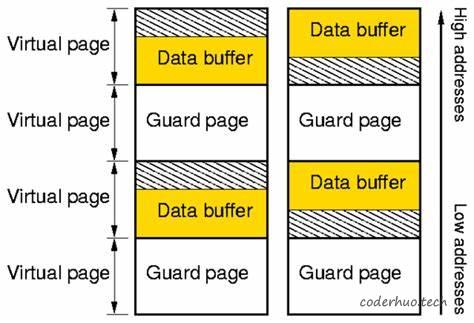
我们打算借鉴其上下边界检测的原理。如下图所示,黄色的Data Buffer部分是用户申请的内存,灰色斜线部分是由于MMU必须按页申请而额外申请的内存,Guard page部分是被设置为不可访问属性的内存页,起保护作用。
下图左侧是向下溢出的检测原理:返回给用户的起始地址是按内存页大小对齐的,然后在用户内存的下边界处放置一个不可访问的内存页,这样当程序访问黄色区域下面的内存时,系统会立马产生异常,就可以抓到谁是凶手。
下图右侧是向上溢出的检测原理:和向下检测不同,这次是把Guard page放在用户内存的上边界处,用户内存的上边界地址必须是按内存页对齐的,下边界就不要求了。
注意:如果代码非法访问灰色区域,efence是检测不到的。
根据上面的原理在本平台上实现了简单的efence代码,遗憾的是,无论是上边界检测还是下边界检测,问题都不再出现。这可能和下面两个因素有关:
- 内存布局被改变导致问题不再复现,因为正常情况下一个信号量才28个字节,但是为了使用MMU的内存保护功能,必须保证信号量的起始地址是4KB对齐的,并且被保护内存区域大小也是4KB的倍数。
- 修改代码导致程序执行顺序发生变化,该出现的问题不再出现了。
至此,一头雾水,我们还是不知道案发现场在哪里。
4.2 加大内存检测频率
前面提到我们托管了内存申请/释放的接口,其实我们不光记录谁申请了多少内存,还在用户内存的前后加了相关标记。通过该标记,可以知道这块内存的前后边界有没有被破坏(踩内存的两种情况:上溢出和下溢出)。另外有个后台线程,定时检测已分配出去的内存有没有被破坏。
内存示意图如下所示(问题排查期间对部分字段做了冗余),图中的数字代表该字段的长度,单位是bit。最前面有个unused区域,这是因为,如果返回给用户的地址按一定字节对齐,前半部分就可能会浪费一小块内存。owner字段填充的是申请本块内存的线程号,通过该字段可以知道这块内存属于谁。

注:该机制还可以用来统计内存的使用情况,检测有无内存泄露。
后台检测线程每秒执行一次检测任务,检测到内存被破坏后打印相关信息。该机制并未检测到这个错误,可能是由于下面两个原因:
- 检测周期较长,死机的时候还没检测到,设备就挂了
- 检测到了,但是打印还没来得及输出(输出是异步的,有缓冲),设备就挂了
抱着试试看的态度,把检测周期改为50ms,并且检测到内存错误后,立即抛出异常,防止其他程序破坏现场。
修改程序后复现,跑出来的结果也是五花八门,而且有些日志还误导了我们,以为找到了凶手,但是排查相关代码,发现那块代码并没问题。
希望再次变成失望。迷茫中,只能对一次次的死机日志进行分析,期望能找到蛛丝马迹。
其中一次死机日志引起了我们的注意,如下图所示,红色方框中是受害信号量,已经面目全非了。奇怪的是,这块内存区域已经被其他线程占用(整个黄色背景区域,已经被线程0xa3921494占用),从内存标记看,这块内存是合法申请的。
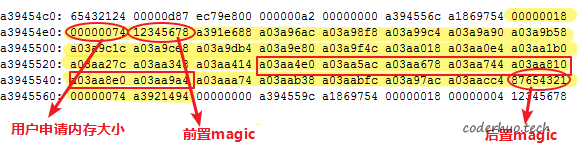
上图对应的内存申请记录如下:
[func1:870:0xa1864a28] malloc:2688197448 bytes. offset:501d513e ptr:0xa394552c
[func2:698:0xa3921494] malloc:116 bytes. offset:c ptr:0xa39454e8
可以看出:
0xa39454e8(func2所申请内存首地址) + 116(十进制) + 12字节的尾部标记 = 0xa3945568 > 0xa394552c(func1所申请内存首地址)
也就是说,两块内存重叠了(func1所申请内存的大小由于被破坏已经没意义了)。严格来说,func2申请的内存块,完全包含了func1的内存块。而func1是先申请的,并且从记录看并没有释放,为啥func2又申请到了这块内存?
难道谁释放了这个信号量所占用的内存?
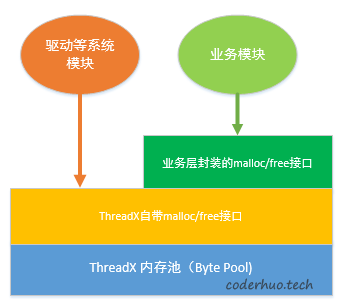
5 谁释放了这块内存
我们设备上的内存接口示意图如下,共有两套接口,其中业务模块的接口做了内存申请释放的统计,可以确认受害信号量所在内存块没有被释放过,但是不排除已通过ThreadX自带的接口被误释放。
5.1 hook ThreadX自带的内存接口
为了确认这块内存有没有被释放,我们打算hook ThreadX的内存管理函数。
链接工具ld提供了–wrap选项,可以在程序链接期间进行符号替换(可参考https://ftp.gnu.org/old-gnu/Manuals/ld-2.9.1/html_node/ld_3.html)。
使用方法:在链接选项(通常为LDFALGS)中增加–wrap symbol,其中symbol为待替换的函数名、全局变量名等。
如果使用了这个选项,程序链接期间引用符号symbol的地方都将被替换为__wrap_symbol(也就是说本来调用函数symbol的地方,将调用函数__wrap_symbol),引用符号__real_symbol的地方都将被替换为symbol(也就是说本来调用函数__real_symbol的地方,将调用函数symbol)。
下面的例子hook了malloc函数,并插入了部分代码。原来程序中调用malloc的地方,都将调用__wrap_malloc,而__wrap_malloc中又调用了__real_malloc,链接期间__real_malloc会被替换为真正的、系统提供的malloc。
void *__wrap_malloc (int size)
{
void *ptr;
/* do something you like before call malloc */
ptr = __real_malloc (size);
/* do something you like after call malloc */
return ptr;
}
按照这个思路,我们hook了ThreadX的内存释放接口_txe_byte_release,发现并没有人释放这块内存。
这就奇怪了,难道ThreadX的内存管理出了问题?
5.2 ThreadX的内存管理机制
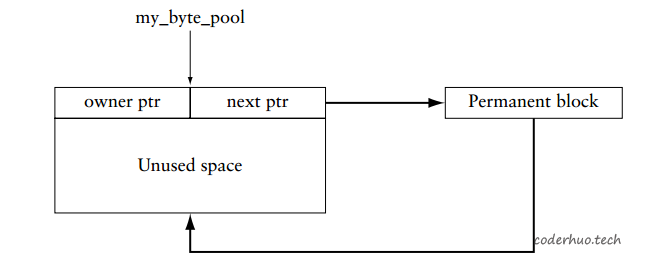
ThreadX的内存池分为Byte Pool和Block Pool两种,前者可分配任意大小的内存块,后者只能分配固定大小的内存块。我们出问题的内存属于Byte Pool,所以这里只讲述Byte Pool相关机制。
Byte Pool是用单向链表管理内存块的,下图是其初始状态。需要注意的是,该链表并不是维护在专有的内存区域,而是直接在本Byte Pool中,如果发生踩内存的情况,Byte Pool的链表有可能被破坏。
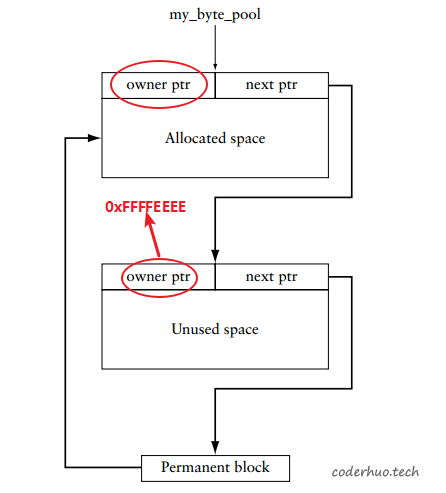
Byte Pool的内存分配方式是first-fit manner(最先匹配原则,与之相对的是best-fit manner),即找到第一个大于用户申请大小的内存块,并根据一定的规则对该内存块进行切割(如果该内存块大小和用户申请内存相差不大,可能就不切割了,直接给用户使用),一分为二,前者给用户使用,后者作为空闲块,留着下次使用。内存申请过程中也可能对多个连续的空闲内存块进行合并操作。
Byte Pool首次分配后的状态如下图所示,注意,如果本内存块已被分配,owner ptr区域填写的是本Byte Pool的地址,如果本内存块未被分配,填充的是0xFFFFEEEE。
5.3 基于内存管理机制进行分析
根据ThreadX的内存管理机制,再次对4.2节提到的重叠内存区域进行分析。可以看到,下图中的[0xa39454d4, 0xa394556c)(两个next ptr之间的内存块)为一个合法的内存块,其owner ptr是正确的,next ptr也确实指向了下一个合法的内存块。而我们可怜的信号量就位于该内存块中,这块内存本属于这个信号量,在无人释放的情况下,又分配给了其他人。

出现该现象,可能是两种原因导致的:
- ThreadX的内存管理模块出了问题
- 内存踩到了特定区域,把ThreadX已分配的内存块标记为Free状态了
既然暂时找不到谁破坏了这块内存,那就先确认下这块内存被破坏的时间,进一步靠近案发现场。
我们加强了内存检测机制,在每次申请/释放内存的时候都对受害信号量进行检查,如果发现异常,立即dump附近内存,并终止程序运行。示例代码如下:
void *__wrap_malloc (int c)
{
void *ptr;
/* 检测受害信号量内存是否被破坏 */
ptr = __real_malloc (c);
/* 检测受害信号量内存是否被破坏 */
return ptr;
}
跑出来的结果让人瞠目结舌,从下图可以看出,红色方框里面的信号量完好无损,但是,这块区域已经被标记为free状态了。接下来如果谁申请内存,这块区域可能就给别人了。
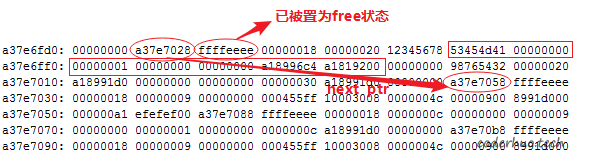
不过本次实验中有个奇怪的现象,检测到信号量异常的位置,总是在malloc或者free的前面。如果是ThreadX的内存管理模块出了问题,检测到信号量异常的位置,应该在malloc或者free的后面。
基于此,可以初步排除ThreadX内存管理模块的嫌疑。但是,如果是踩内存的话,偏偏只踩了中间的0xffffeeee这四个字节,而且前面的内容没踩,后面的内容也没踩,更诡异的是,被踩区域写入的恰好是ThreadX的内存free标记。
难道ThreadX的内存管理模块不是线程安全的? 从github上的源码和实际工程的反汇编看,应该是线程安全的。为了排除该嫌疑,我们特意在hook后的malloc/free中加了把锁,结果问题还是可以出现。该嫌疑被排除。
如果把ThreadX的内存free标记改为其他的呢?踩内存的现象还会出现吗?出现的话,被写入的还是0xffffeeee吗?
基于该想法,我们把github上Byte Pool的代码移植到设备上(实际工程中Byte Pool的代码我们拿不到,无法调试,和供应商确认过,github上的代码和他们提供给我们的差别不太大),并且做了以下两点改动:
- 将内存free的标记改为0xaaaabbbb。
- 在每个标记内存块为free状态的地方加了判断,如果被free的内存块是那个信号量的,直接抛出异常。
很幸运,该代码完全可以运行,而且问题还能复现。根据复现现象,我们得到以下信息:
- 被踩区域仍然是那个信号量
- 进一步确认了上面的推断:不是内存管理模块将那个信号量释放的
- 不可思议的是,被踩区域被写入的不再是0xffffeeee, 而是0xaaaabbbb
现在可以确认是踩内存问题了。 但是谁踩的呢? 这踩的也太有技术了,在相对固定的位置,写下具有特殊含义的数值,该数值还和ThreadX内存free的标记保持同步。
我真是太佩服写这个bug的人了,大写的NB!!!
6. 谁踩了这块内存
转了一圈,又回到了原点。现在梳理下目前的排查情况:
- ThreadX内存管理模块的嫌疑已排除。
- 内存踩的很有技巧,相对位置固定的地址,前面的内容不破坏后面的内容不破坏,偏偏只破坏了中间的四个字节,而且这四个字节和内存管理模块free状态的magic code保持一致。
这时,基本无思路了,问题就在那里,但就是抓不到凶手。不甘心,又瞎折腾了几种定位方法,虽然知道基本上无效,但是希望能影响执行时序,跑出不一样的日志,找到新线索:
- hook了memcpy、memmove、strcpy等内存操作函数,在内部检查有没有破坏那个信号量,结果没啥新发现。
- 从反汇编中看哪些地方会写0xffffeeee到内存区域,其实从上面的实验就可以知道该方法无效了,因为即使改为0xaaaabbbb问题仍然出现。
- 开启栈保护功能,原理和操作方法可以参考《如何在实时操作系统(RTOS)中使用GCC的栈溢出保护(SSP)功能》。同样,从上面的分析结果看,该问题不像是栈溢出导致的。实际证明加上该机制仍然没啥新发现。
6.1 硬件watchpoint
现在最有效的定位手段就是,对那四个字节做写保护,但是前面提到的MMU做不到,因为MMU的最小保护单元是一个内存页,一般为4KB。
关键时刻,驱动组同事有了新想法,Linux下可以通过gdb的watchpoint监控特定内存区域,我们的系统是否也可以引入类似的机制?
通过gdb相关代码可以看到,它是利用了arm的协处理器cp14来实现的,该机制是芯片自带的,和操作系统、调试工具无关,我们的平台也可以支持。具体原理和操作方法可以参考《如何利用硬件watchpoint定位踩内存问题》。
Demo实测证明该工具超级好用,完全可以满足我们的需求。感觉终于要到开奖的时刻了,只等问题复现。
然而,现实再次给了我们一巴掌。问题复现出来了,但是该机制没检测到。真让人抓狂!!!
6.2 浮出水面的DMA
有个特殊内存块(256KB),在整个问题定位过程中,一直被我们怀疑来怀疑去,但总是找不到具体的证据。该内存和受害信号量所在内存紧挨着,并且位于受害信号量前面。几波人反复走读过相关代码找不到可疑点。但是,每次问题出现的时候,它总是和受害者相邻。
[某线程的内存 ]Index:385 Type:1. size:262172 caller:0 mem_addr:a37a6fb8 Tick:0 Diff:262180
[受害信号量内存]Index:386 Type:1. size:76 caller:0 mem_addr:a37e6fdc Tick:0 Diff:0
驱动同事问“这个内存是干嘛的”,答“读写TF卡文件用的”。这时驱动同事恍然大悟,“怪不得watchpoint抓不住,搞不好就是它了,因为Cache操作不会触发watchpoint”。

读写文件是经过DMA拷贝的,而我们的系统上是有Cache的,这个过程涉及Cache和主存的同步。
6.3 杀手现身
首先我们不再从内存池中动态申请这256KB内存,而是以全局数组的形式在编译期就分配好,复现了一段时间,问题果然没出现。当然不能凭此给它定罪,因为我们的问题本身出现概率就不高,有可能是改代码导致执行时序等发生变化,问题不再出现。
接下来我们进行正面验证。我们以全局数组的形式在编译期申请了512KB内存,前256KB给嫌疑模块正常使用(后面称为A),后256KB写入固定的内容(后面称为B),然后周期性检测后半部分会不会被修改。实验表明,问题没再出现,B也没被篡改,仍然没法给它定罪。
仔细想想,上面的验证逻辑有问题。假设是DMA导致的踩内存,那应该是在Cache和主存同步过程中出现的,也就是说二者的一致性出问题了。但上面的例子中,B中的内容永远是固定的,也就是说Cache和主存中是一致的。我们需要构造Cache和主存不一致的情况。
下面的代码看起来很不可思议(全局数组mem_for_sd的后256KB,即上面提到的B,只在函数change_and_check_mem中使用),先把B赋值,然后过一会再检查有没有被修改。函数change_and_check_mem在后台线程中周期性执行。

更不可思议的是,问题很快就复现了。如下图所示,0xa182f710是B的起始地址,可以看到,有16个字节被破坏了。整个过程描述如下:
- 上次change_and_check_mem执行完,整个B被填充为0x34
- 本次执行change_and_check_mem时,先将B的填充改成0x49
- 休眠10ms
- 对B检测,发现B的前16个字节被改为0x34,而0x34是B的历史值,红色方框里也应该被填充为0x49

该实验证明了:真凶在此!!!
由于整个B中被填充的都是同一个值,下面两种情况无法区分:
- B前16个字节的值被缓存,而后又被赋值到原来的位置
- B的某个字节的值被缓存,而后又将该值填充到B的前16个字节(如果是这种情况,就不太像是DMA导致的了)
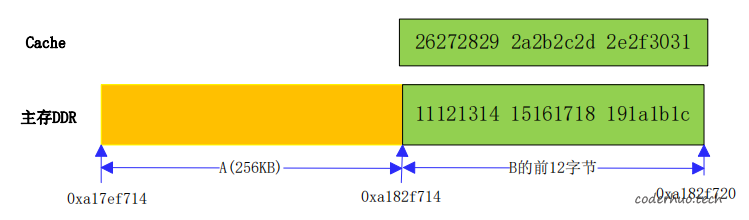
为了摸清规律,我们又进行了下面的实验。和上面实验的不同之处在于,B中的值不再是一样的,而是从一个随机值递增的,到0xFF则回归到0x0。

问题很快就又出现了,结果如下图所示,0xa182f714是全局数组B的起始地址,可以看到,有12个字节被破坏了。整个过程描述如下:
- 上次change_and_check_mem执行完,B的起始地址被填充为0x11,后面依次为0x12,0x13,每个字节加1,遇到0xff变为0x00
- 本次执行change_and_check_mem时,修改B的填充,起始地址填充为0x26,后面依次为0x27, 0x28, 每个字节加1,遇到0xff变为0x00(这部分在下面的截图中看不出来,因为已经被踩了)
- 休眠10ms
- 对B检测,发现B的前12个字节被改为11121314 15161718 191a1b1c(下图红色方框内的数据),而这些值是B的历史值。红色方框内的数值应该为26272829 2a2b2c2d 2e2f3031。

从这次实验结果看,应该是B前面几个字节的值被缓存,而后又被赋值到原来的位置。不过值得注意的是,B这次被踩了12个字节,而不是16个字节。结合B的首地址和被踩字节数,可以发现最终得到的都是0xa182f720(该值为32的倍数)。也就是说被踩字节数和首地址是有关联的。
第一次试验: 0xa182f710 + 16(十进制) = 0xa182f720
第二次试验: 0xa182f714 + 12(十进制) = 0xa182f720
6.4 DMA与Cache一致性
DMA会导致Cache一致性问题。如下图所示,CPU的运算操作会修改Cache中的数据,而DMA会修改主存DDR中的数据,这就要求二者需要通过一定的机制保持同步,即Cache一致性。

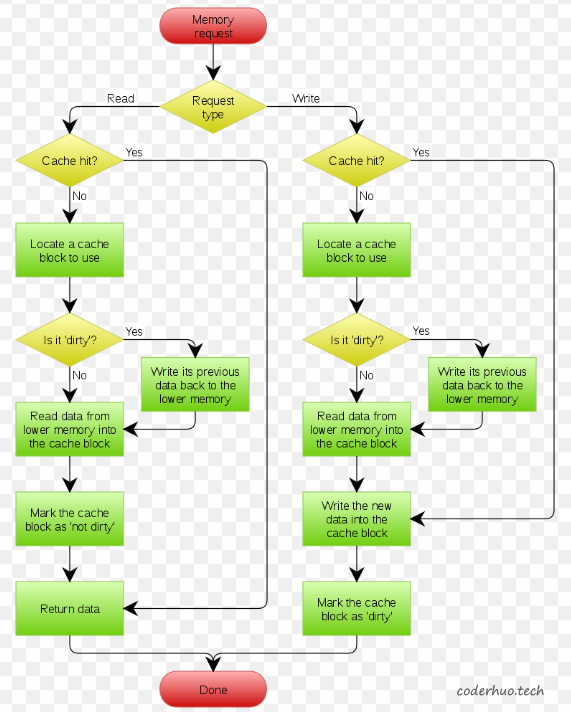
下面的流程图展示了在内存读写过程中,Cache是如何与主存同步的,注意下面三点:
- dirty的Cache在被置换出去的时候,必须回写到主存(下图中的lower memory)
- Cache未命中的时候,是从主存中读取原始数据的
- CPU修改Cache中的数据后,并未直接回写到主存,而是将该Cache标记为dirty
了解了上面的原理,我们结合DMA分析下磁盘文件的读写流程。
写数据到磁盘:
- 判断Cache中的数据是否为dirty,如果dirty就回写到主存DDR
- 启动DMA将数据从主存搬运到磁盘
从磁盘读数据:
- 启动DMA将数据从磁盘搬运到主存DDR
- 将对应主存区域的Cache全部置为无效(invalid cache,注意不是dirty,这样程序访问的时候,才会从主存读取最新数据)
6.5 幕后主使在此
驱动同事分析DMA相关代码,发现本平台的Cache Line为32字节,DMA操作的时候,未考虑Cache Line的对齐问题,导致Cache与主存的一致性出了问题,进而在文件读取的时候破坏了相邻的内存(大家可以思考下,为什么写文件的时候没有出问题)。以6.3节第二次实验为例,具体原因如下:
-
程序从文件中读取256KB的数据到下图中的内存区域A,和A紧挨着的内存区域B为另一个线程的,B的前12字节在主存中的内容和Cache中的内容不一致(结合上面介绍的知识,我们知道这是正常的)。
-
DMA将文件读取到主存的A区域后,需要将A区域对应的Cache invalid(失效)掉,以保证Cache和主存中的数据是一致的。
注:实际上,A对应的内存区域可能已经不在Cache中了,但DMA不知道,为了保证数据的一致性,它必须将A对应的Cache invalid掉。 -
Invalid Cache的时候就带来问题了。前面提到本平台的Cache Line为32字节,也就是说一次进入Cache或清除Cache的最小单位是32字节,而A的首地址为0xa182f714,大小为256KB,为了保证整个A区域的Cache被清除,必须清除至地址0xa182f720。计算方法为:按32字节的倍数向上对齐,如下所示:
ROUND_UP(0xa182f714 + 0x40000, 32) = 0xa182f720 -
B现在最新的数值是在Cache中,而上面的操作会将B前12字节对应的Cache invalid掉。如下图所示,后续程序再访问B的前12字节,cache未命中,只有从主存中取,结果取到的是历史值。
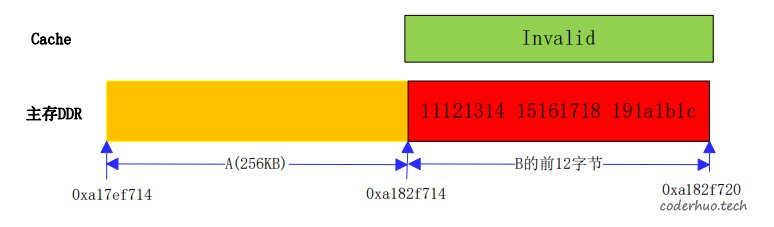
就这样,B躺着中枪了!!!
实际程序中,那个可怜的信号量就在上面的B处。
7. 修改方法
由于本平台的Cache Line为32字节,所以我们需要保证拿去做DMA的内存首地址32字节对齐,并且大小也是32字节的倍数。这样就不会出现上面的踩内存问题。
7.1 方法一:应用层规避
所有使用DMA的业务代码,自行保证内存首地址和大小均按32字节对齐。但是该方案存在以下明显的缺点:
- 上层业务必须知道哪些接口是使用DMA的
- 有些内存变量的对齐不好做,比如栈上的局部变量
- 增加了上层业务开发的复杂度
7.2 方法二:驱动层规避
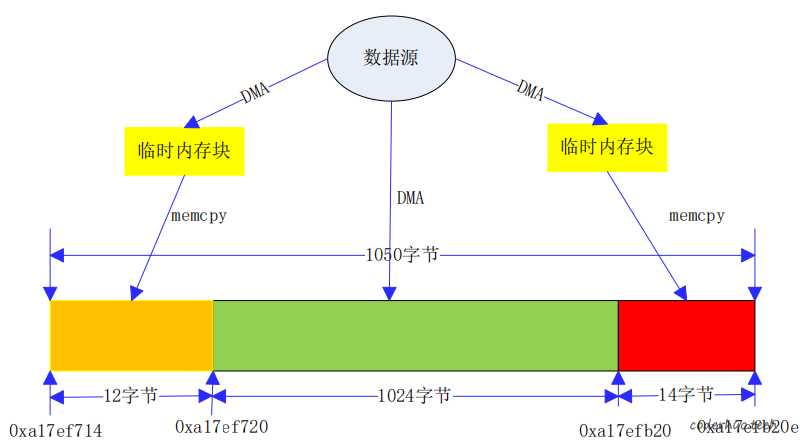
比较合理的解决方法是,驱动层保证。如下图所示,驱动层识别到首地址不是32字节对齐的,就先用一个临时内存块(该临时内存块首地址32字节对齐,大小是32字节倍数)做前12字节的DMA,然后将前12个字节通过memcpy拷贝到主存的0xa17ef714~0xa17ef720,接下来的1024字节因为满足对齐和大小要求,所以可以直接进行DMA,尾部剩余14字节只满足首地址对齐的要求,不满足大小是12字节倍数的要求,所以也要借助临时内存完成数据搬运。
8 总结
本文涉及的知识点如下:
- backtrace回溯函数调用栈
- 汇编代码分析
- 内存打标记,及基于此的内存非法访问检测
- 基于MMU的内存保护
- Electric Fence(efence)内存非法方法检测机制
- 通过wrap链接选项替换系统函数
- 基于GCC的栈溢出保护(SSP)功能
- 硬件watchpoint
- TheadX内存管理机制、信号量管理机制
- DMA、Cache一致性
9 参考资料
- ThreadX源码
- arm平台根据栈进行backtrace的方法
- real-time-embedded-multithreading-using-threadx-and-arm.pdf
- https://linux.die.net/man/3/efence
- 函数wrap原理
- https://en.wikipedia.org/wiki/Cache_(computing)#WRITE-BACK
- https://en.wikipedia.org/wiki/Cache_coherence
- 如何在实时操作系统(RTOS)中使用GCC的栈溢出保护(SSP)功能
- 如何利用硬件watchpoint定位踩内存问题
